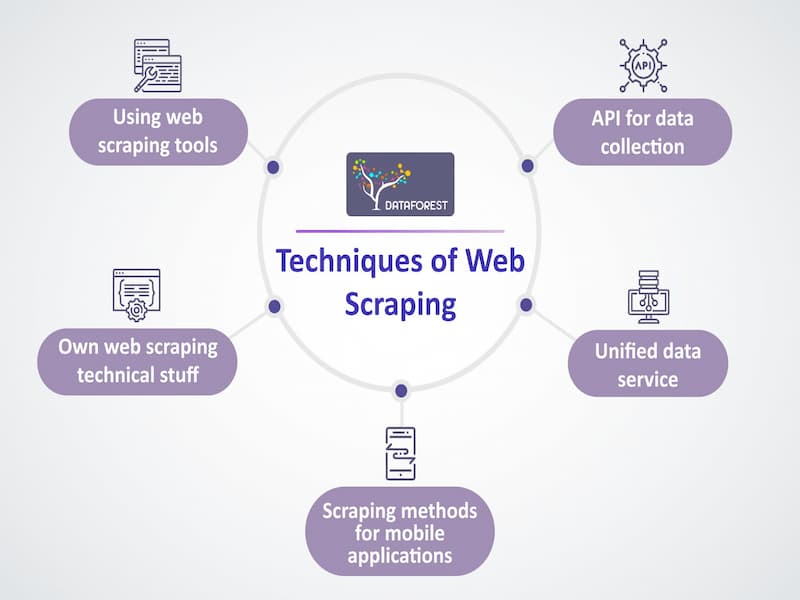
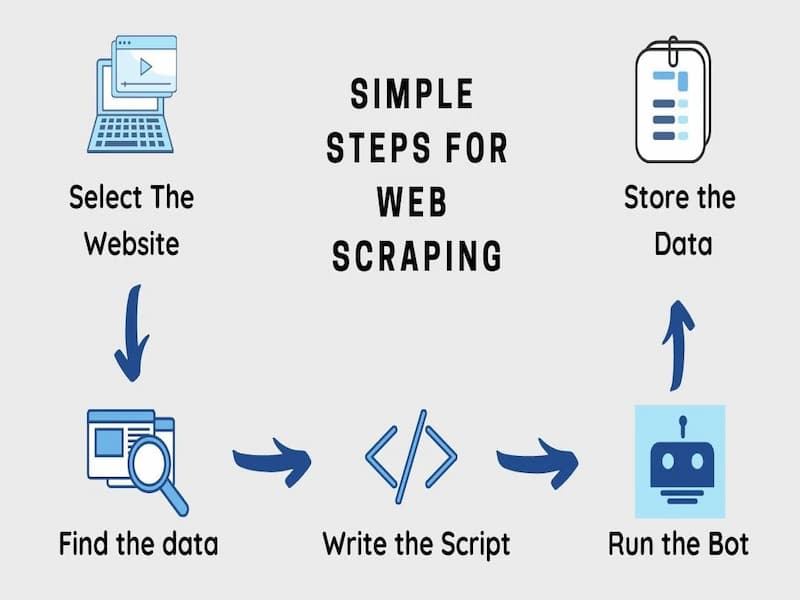
About the Project
The Web Scraping Project is a specialized initiative designed to automate data collection from various online sources. By utilizing advanced scraping techniques, this project aims to extract, clean, and structure data efficiently, enabling stakeholders to gain valuable insights and support data-driven decision-making.
Project Objectives
The primary goal of the project is to develop a robust framework for web scraping that ensures data accuracy, reliability, and compliance with ethical and legal standards. Specific objectives include:
- Automating the extraction of large-scale data from diverse web platforms.
-
Cleaning and structuring raw data to make it analysis-ready.
-
Providing actionable insights for stakeholders through organized datasets.
Scope of Work
The Web Scraping Project includes the following key activities:
- Source Identification and Analysis : Identifying reliable online sources for targeted data collection.
- Scraping Development : Building and optimizing web scraping scripts using Python libraries such as BeautifulSoup, Scrapy, or Selenium.
-
Data Cleaning and Validation : Cleaning scraped data to remove inconsistencies and ensure completeness and accuracy.
-
Data Storage and Integration : Storing the processed data in accessible formats such as CSV, JSON, or databases for analysis.
-
Compliance Checks : Ensuring that all web scraping activities adhere to legal regulations and ethical standards.
Expected Impact
This project is expected to deliver significant value, including:
- Enhanced Data Accessibility : Providing structured data from previously unstructured or inaccessible web sources.
- Time and Cost Efficiency : Reducing manual data collection efforts through automation.
-
Improved Decision-Making : Supporting stakeholders with timely and accurate data for analysis.
-
Scalable Frameworks : Enabling future expansion and adaptation to scrape different types of data across industries.